
Bisher nutzte ich für die Konvertierung von Texten für DokuWiki das Plugin Writer2Dokuwiki und hatte wenig Probleme. Das jetzt frisch verfügbare LibreOffce 5.1 schmiert mir hierbei jedoch kommentarlos ab, so dass ich auf die Schnelle eine andere Möglichkeit brauchte. Diese ist nun eine Kombination aus tidy und pandoc.
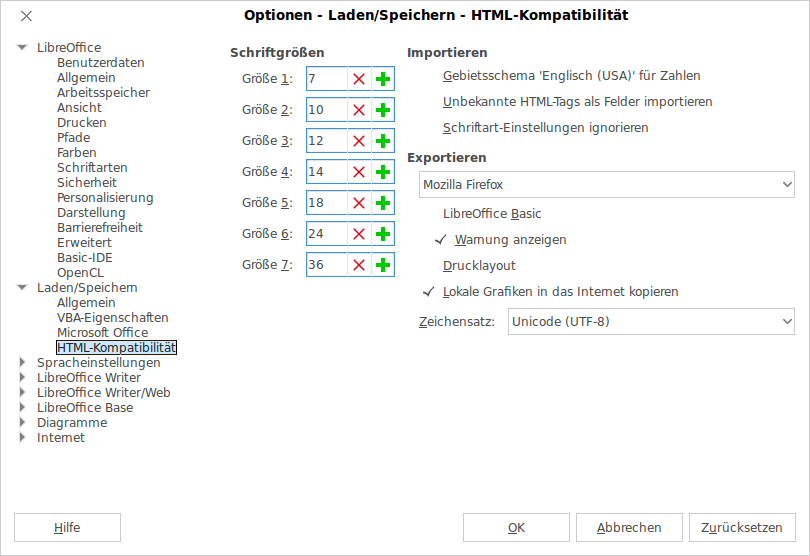
In LibreOffice wird das Exportformat für HTML Dateien zuerst unter /Extras /Optionen /Laden-Speichern /HTML-Kompatibilität auf UTF-8 umgeschaltet.
Über /Datei /Speichern unter wird nun das HTML-Format ausgewählt und die Datei gespeichert.
Hinweis: Der Exportdialog unter /Datei /Exportieren… erzeugt XHTML Dateien, die noch schwerer zu putzen sind. Also nutze ich diese Funktion nicht.
Der von LibreOffice erzeugte HTML-Code ist grauenhaft. Also muss dieser mit tidy geputzt werden. Die tidy.conf liegt hierbei in meinem Stammordner im dortigen ~/bin Verzeichnis:
# /home/dirk/bin/tidy.conf clean: yes drop-proprietary-attributes: yes drop-empty-paras: yes output-html: yes input-encoding: utf8 output-encoding: utf8 join-classes: yes join-styles: yes show-body-only: yes force-output: yes
Ein
tidy -q -config /home/dirk/bin/tidy.conf -i inputdatei.html | sed 's/ class="c[0-9]*"//g' > geputzt.html
wirfft weg, was wir nicht brauchen. Ein bischen class=western kann dabei übrig bleiben, tut aber nicht weiter weh.
Als nächstes kommt pandoc in einer Version größer gleich 1.13 zum Einsatz (unter Ubuntu 15.10 vorhanden):
pandoc -s -r html geputzt.html -t dokuwiki > fuerdokuwiki.txt
Die TXT Datei dann mit einem Editor öffnen und den Inhalt in DokuWiki einfügen. Voila. Zusammen macht das dann
tidy -q -config /home/dirk/bin/tidy.conf -i inputdatei.html | sed 's/ class="c[0-9]*"//g' | pandoc -s -r html -t dokuwiki > dokuwiki.txt ; kate dokuwiki.txt
oder gleich als Skript verpackt:
#!/bin/bash tidy -q -config /home/dirk/bin/tidy.conf -i $1 | sed 's/ class="c[0-9]*"//g' | pandoc -s -r html -t dokuwiki | leafpad
Das klappte hier mit less und leafpad, das von mir sonst bevorzugte kate wollte nicht von stdin lesen. Da muss ich noch einmal nachsehen, woran das lag.
Man kann auch den Aufruf von LibreOffice und damit den ersten Schritt in das Skript integrieren, sofern die (angelieferten) Dokumente mit Formatvorlagen erstellt wurden. Das ist in meinem Kollegium hoffnungslos – aber im Prinzip ginge ein
soffice --headless --convert-to html:HTML datei.doc