
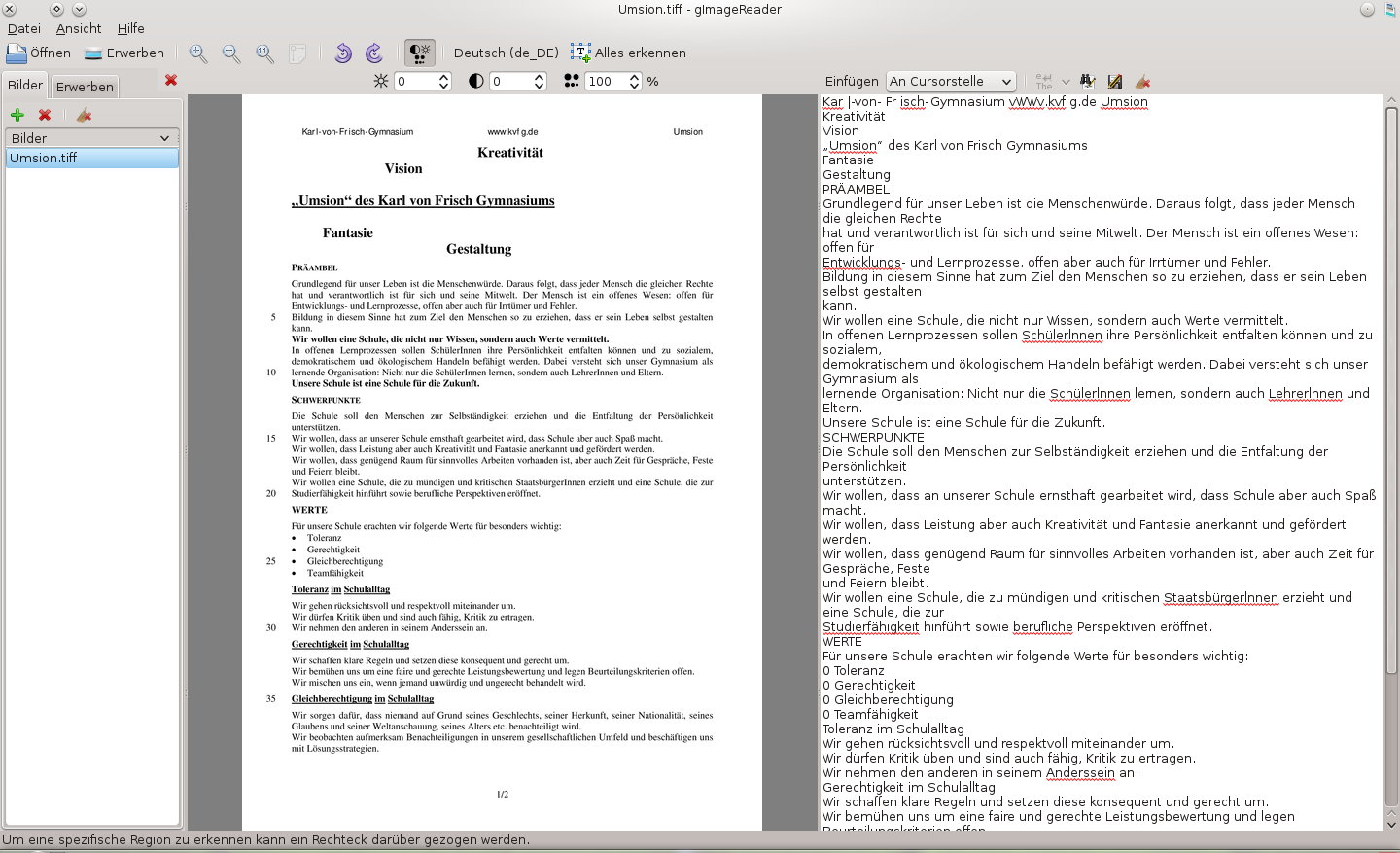
Tesseract befindet sich in einer aktuellen Version in den Repos von Fedora 18 (sowie Ubuntu) und gimagereader ist als RPM für Fedora 15 / als DEB für Ubuntu nach Installation einiger Voraussetzungen nicht nur installierbar, sondern arbeitet rund.
Die Voraussetzungen werden mit RPM bei einem
rpm -i gimagereader-0.9-1.fc15.noarch.rpm
angezeigt und sind zügig an Bord geholt:
yum install gnome-python2-gtkspell pypoppler python-imaging-sane
Wer unter Ubuntu mit gdebi, qapt oder über das Softwarecenter installiert, zieht die Abhängigkeiten automatisch mit.
Die Erkennungsleistung ist schon bei 300 DPI Scans hervorragend und kann durchaus mit kommerziellen Produktion mithalten – selbst bei kursivem Text oder leicht schrägen Vorlagen.
Was man von dieser Lösung nicht erwarten darf, sind Mehrfachtextboxen oder gar ordentliche Erkennungsleistungen bei Tabellen. Was auch nicht geht, ist der Export von Bildern oder des Layouts aus dem Scan in die Textdatei. Tesseract liefert plain text. Wer mehr will, kann z.B. das sehr gute Online-OCR von Finereader benutzen: http://finereader.abbyyonline.com/